Designing with Simplicity in Mind
Before jumping into development, the first and most important step was to deeply understand the requirements. The goal wasn’t just to make it work — but to design the simplest possible solution that is reliable, scalable, and easy to maintain.
The initial requirements were clear:
- Ingest a list of the top 250 movies from an S3 source
- Filter the top 10 entries
- Enrich each movie with metadata from an external API
- Store the final, enriched data back in S3
Core Architecture: The Minimal Viable Flow
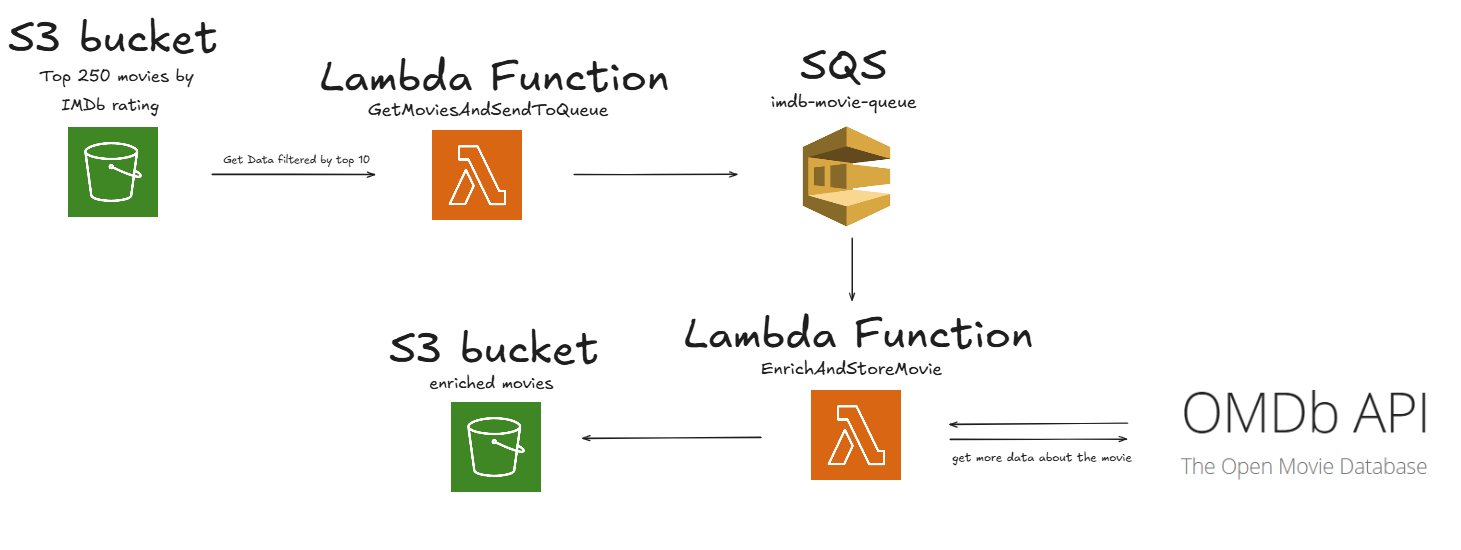
To meet these goals effectively, I designed a minimal yet complete serverless data pipeline, composed of two core components:
1. GetMoviesAndSendToQueue (Lambda Function)
This function is responsible for:
- Reading the original dataset from a public S3 bucket
- Filtering the top 10 movies
- Sending each movie as a message to an Amazon SQS queue
This approach ensures asynchronous processing and decouples ingestion from enrichment.
2. EnrichAndStoreMovie (Lambda Function)
Triggered by each message in the queue, this function:
- Calls the OMDb API using the IMDb ID
- Enriches the movie data with additional details
- Stores the final, enriched movie JSON object into a designated S3 bucket
Key Benefits of the Core Design
- Simplicity: Just two Lambda functions and an SQS queue
- Scalability: Fully event-driven and asynchronous
- Extendable: Serves as the foundation for more advanced features (e.g., medallion layers, scheduled batches, BI)