S3 Buckets
This project follows the Medallion Architecture to organize and track the evolution of data across different levels of refinement. To support this, three Amazon S3 buckets are provisioned and configured automatically using AWS SAM:
| Layer | Purpose | Content Example |
|---|---|---|
| Bronze | Raw data from OMDb & IMDb | Multiple JSONs (1 per movie) |
| Silver | Normalized & enriched records | Normalized CSV dataset |
| Gold | Final curated datasets | Structured CSV datasets |
By structuring the pipeline into layers, we ensure clarity, modularity, and traceability of data as it moves through the ETL process.
Bucket Provisioning with SAM
Each bucket is created declaratively through template.yaml. Example for the Bronze layer:
BronzeBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Ref BronzeBucketName
PublicAccessBlockConfiguration:
BlockPublicAcls: true
BlockPublicPolicy: true
IgnorePublicAcls: true
RestrictPublicBuckets: trueThis ensures:
- Restricted Access: Public access is fully blocked to enforce security best practices.
- Declarative Infrastructure: All bucket configurations are managed via Infrastructure as Code, ensuring reproducibility across environments.
- Automated Setup: Buckets are created and configured automatically during
sam deploy, with no manual steps required.
Example Bucket Structure
Below are example screenshots from the AWS S3 Console, showing files organized in each bucket:
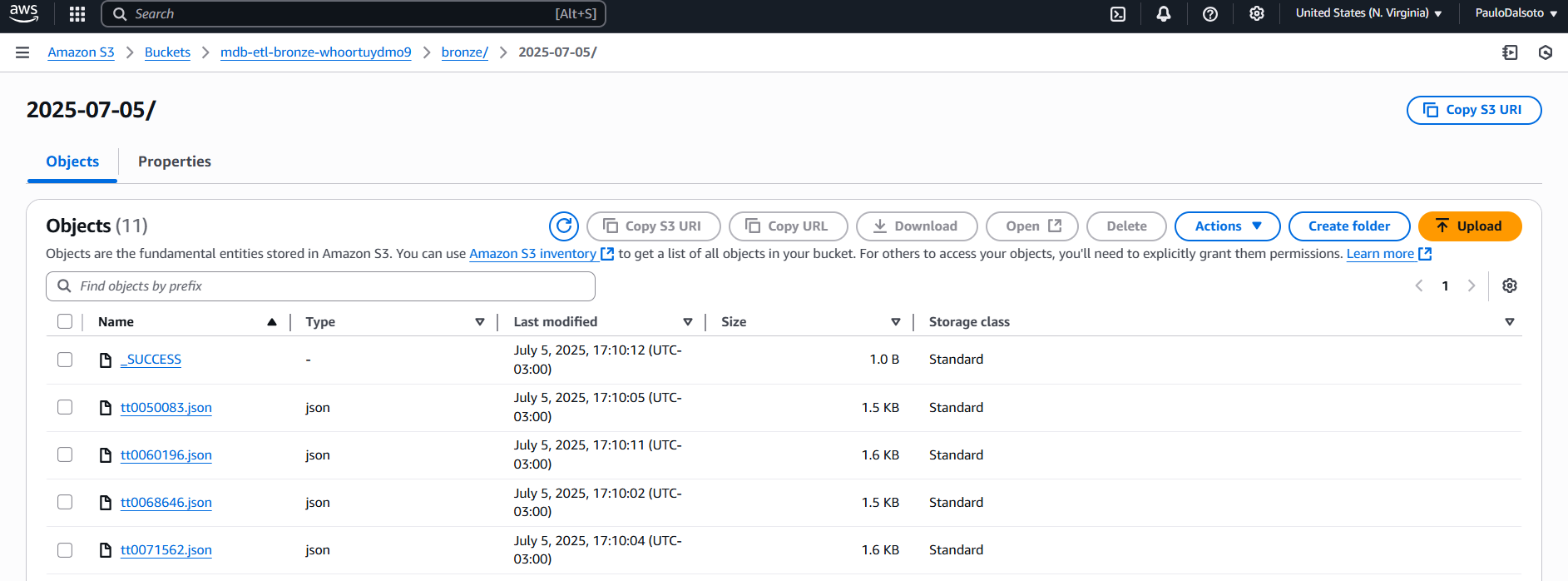
bronze/ folder: Raw movie data from OMDb
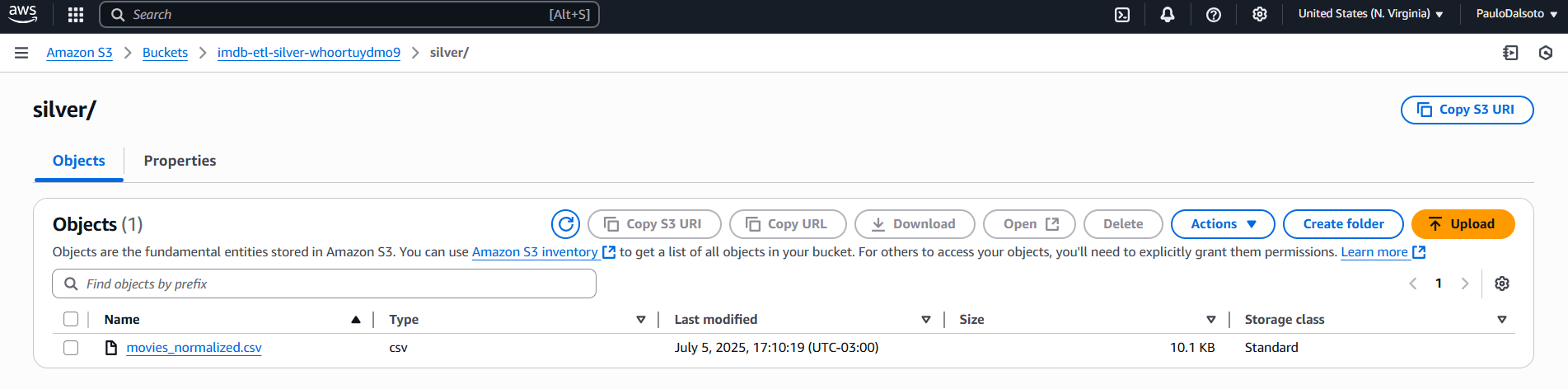
silver/ folder: Normalized movie data
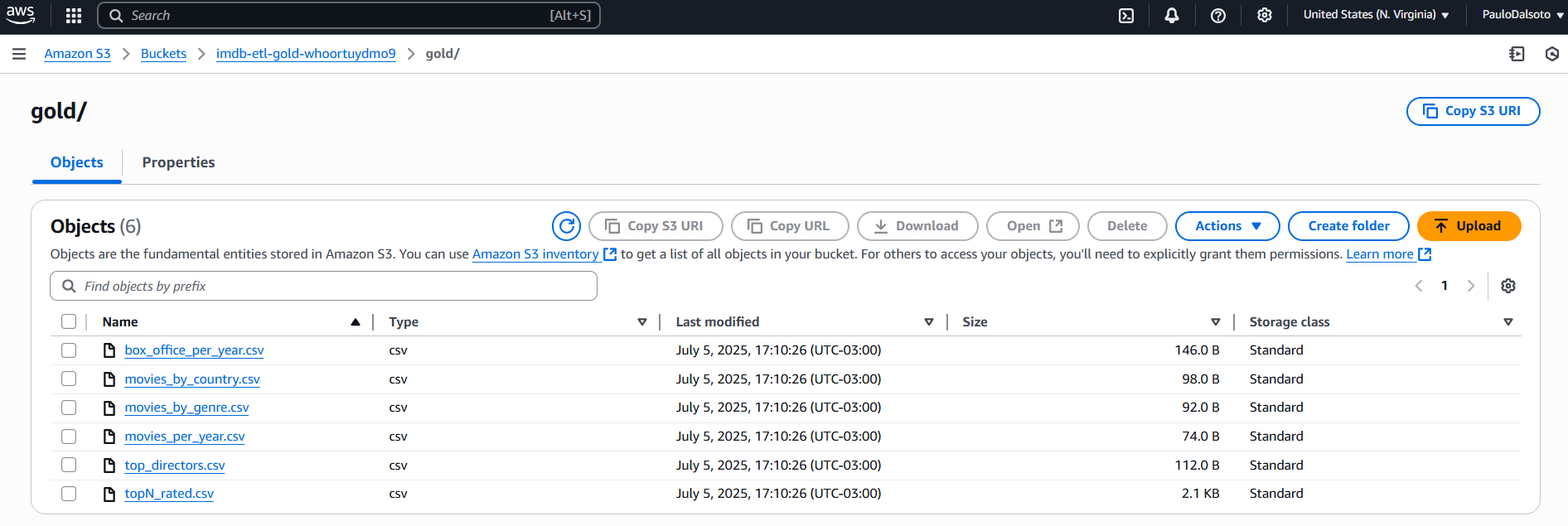
gold/ folder: Ready-to-use datasets
Learn More
To explore the S3 buckets and their configurations, you can access them directly via the AWS Console:
For complete configuration and provisioning details, see the Infrastructure as Code (IaC) section.
To understand the data layering logic, refer to the Medallion Architecture section.