Event Triggers
This project follows an event-driven architecture to orchestrate its ETL pipeline from end to end, relying on automated triggers to execute each stage in sequence without human intervention.
How the Pipeline is Triggered
The ETL flow is fully chained and begins with a time-based trigger defined in AWS EventBridge, which invokes the first Lambda function.
From there, each subsequent function is triggered automatically by events generated in AWS services such as Amazon SQS and Amazon S3:
Chained Execution
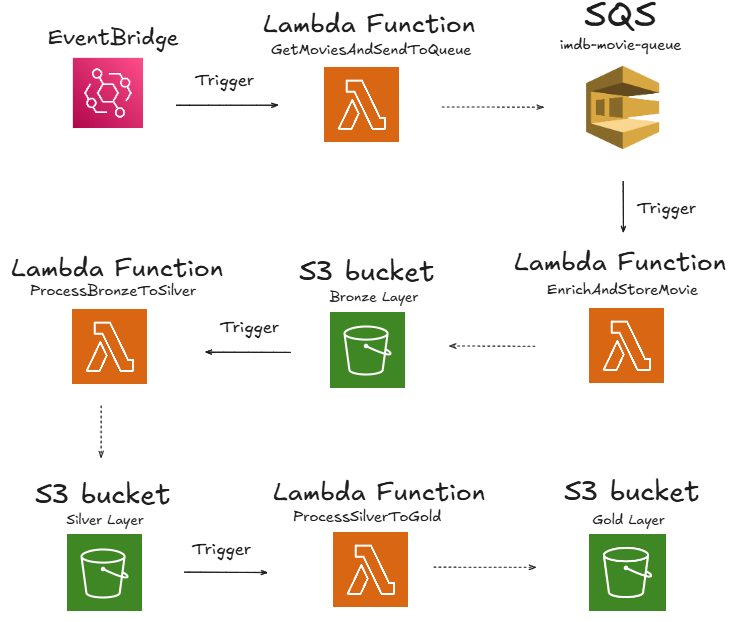
Here’s a high-level overview of how each step is linked:
- EventBridge triggers GetMoviesAndSendToQueue daily at
03:00 UTC. - This function sends batches of movies to the SQS Queue.
- Each message in the queue triggers the EnrichAndStoreMovie Lambda, which fetches enriched metadata from OMDB and stores it in the Bronze layer on S3.
- Once all movies are processed, the Lambda writes a
_SUCCESSfile — this triggers the ProcessBronzeToSilver function via an S3 event. - That function reads raw JSON files from the Bronze bucket, normalizes them, and writes a single CSV to the Silver layer.
- The creation of this CSV triggers the ProcessSilverToGold Lambda, which generates analytical datasets and stores them in the Gold layer on S3.
Each step in the pipeline is fully decoupled, yet seamlessly orchestrated through AWS-native triggers.
Fully Automated Processing
By leveraging this event-driven design, the ETL pipeline can run autonomously — from data extraction to enrichment, transformation, and analytics generation — without the need for external schedulers or manual interventions.
This approach ensures:
- Scalability: each function can scale independently.
- Reliability: built-in retries and monitoring are easier to apply per step.
- Maintainability: logic is isolated, and failures are easier to track and recover.